Context-Dependent Pitch Prediction with Neural Networks
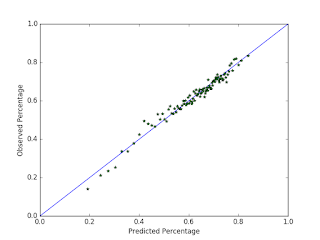
This semester I took the machine learning class at UMass, and for my final project I developed models for predicting characteristics of pitches based on the context that they were thrown in. The context consists of relevant and available information known before the pitch is thrown, such as the identities of the batter and pitcher, the batter height and stance, the pitcher handedness, the current count, and many others. In particular, I looked into modeling the distribution over pitch types and locations. This problem is challenging primarily because for a particular context (a specific setting of the different features that make up the context), there is usually very little data available for pitches thrown in that context. In general, for each context feature we include, we have to split up our data into $k$, groups where $k$ is the number of values that the context feature can take on (for batter stance it is $k=2$, for count it is $k=12$, etc). Thus, de...