Beat the Streak: Day Five
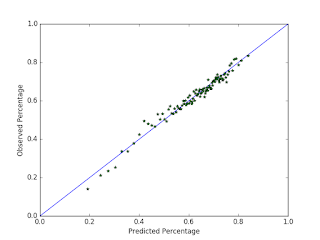
With the recent high offensive production in the mlb, many people have amassed large streaks in the Beat the Streak contest. The current leader has a streak of 41 games, which he got by picking exclusively red sox players. Many other people have streaks in the high 30s, and I have a streak of 19 myself right now. It seems like a lot more people have been getting longer streaks this year. Some of this is probably due to the fact that more batters are getting hits this year than they have in the past, but it is probably also due to MLB.com's new pick selection system, which makes it easier than ever to make high quality picks using whatever strategy you want. I would not be surprised if this is the year somebody wins. If that's the case, this could be one of my last blog posts on this topic. In this blog post, I am going to evaluate my current pick selection strategy by testing it on data from 2015. My data consists of a list ...